YOLOX: Exceeding YOLO Series in 2021
Introduction
YOLO 시리즈는 항상 속도와 정확도간의 최적의 trade-off를 갖는 것을 추구했습니다. 하지만 현재 one-stage object detector들은 모두 anchor-free를 추구하고 더 나은 레이블기법들을 사용하고 있습니다.
따라서, anchor-free를 만족시키는 것을 목표로 YOLOX를 개발하게 되었습니다. YOLOX의 베이스는 YOLOv3-SPP에서 시작되었습니다.
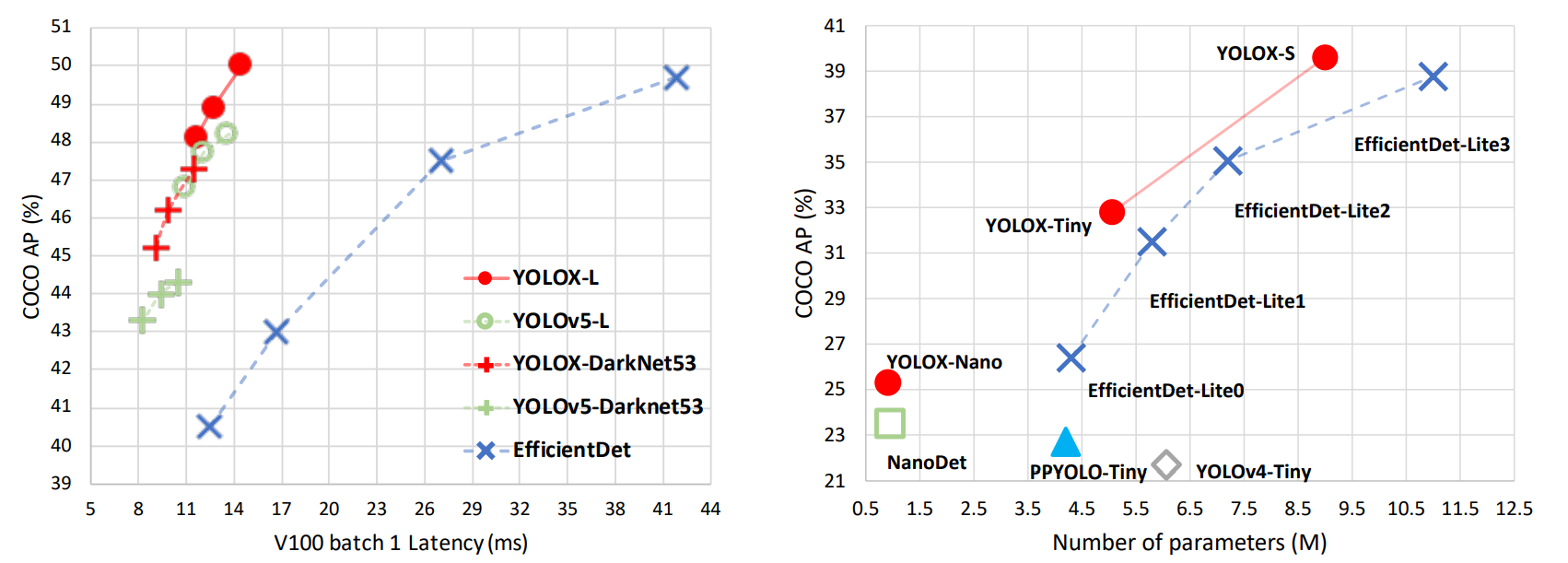
그 결과 YOLOX는 YOLOv3(44.3% AP)보다 높은 50.0%AP를 달성하였으며 YOLOv4-Tiny에 대응할만한 YOLOX-Nano는 10%AP 앞서게 되었습니다.
YOLOX
YOLOX-DarkNet53
- Implementation details
- SGD(Stochastic Gradient Descent)
- Learning Rate = lr * BatchSize/64(linear scaling, initial = 0.01, cosine lr schedule)
- wegith decay = 0.0005, SGD momentum = 0.9
- Batch Size = 128
- YOLOv3 baseline
- backbone = DarkNet53, SPP layer
- EMA weights updating
- cosine lr schdule
- IoU loss for training
regbrannch - BCE Loss for training
cls,objbranch - Augmentation = RandomHorizontalFlip, ColorJitter
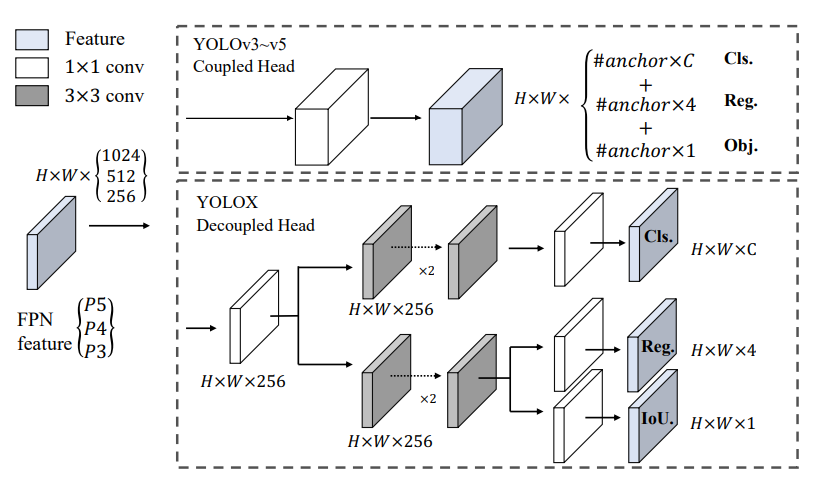
- Decoupled head
- 아래와 같이 anchor사이즈별로 class와 offset들과 객체 유무를 판단하는 것이 아니라 각각 다르게 loss를 계산하는 decopuled head를 제안하게 되었습니다.
- channel dimension을 줄이기 위해 1 X 1 conv layer를 추가하고 그 뒤에 두개의 3x3 conv layer를 추가한 형태를 띄게 됩니다.
- Strong data augmentation
- Mosaic and MixUp기법을 사용하였는데 이는 포스트 후반부에 어떻게 적용시켰는지 확인해보겠습니다.
- NO PRE-TRAINING ImageNet
- Anchor-free
YOLOv4와 YOLOv5는 YOLOv3에서 파생된 anchor-based 파이프라인을 따르지만 anchor-based 파이프라인은 몇가지 문제가 존재합니다.
- 최적의 검출 성능을 위해서 학습 이전에 클러스터링 과정을 통해 anchor size를 설정해야합니다.
- detection head에 복잡성을 더하게 됩니다.
- 이는 많은 양의 추론을 위해 NPU에서 GPU로 이동할 경우 큰 오버헤드를 갖게됩니다.
기존의 3개의 anchor를 regression하는 것이 아닌 1개의 box를 예측하게 되는데 이는 left-top corner of the grid의 offset과 predicted box의 width와 height을 찾게 됩니다.
이는 parameter들과 GFLOP들을 줄여주지만 더 나은 성능을 가지게 됩니다.
- Multi positives
- 위의 anchor-free방법을 적용할 경우 오직 한개의 positive sample을 예측하게 되고 이는 곧 많은 negative sample이 나와 굉장히 큰 불균형을 초래하게 됩니다.
- 따라서, FCOS의 “center sampling”을 통해 the center 3 X 3 area를 positive sample로 할당합니다.
- SimOTA
더 나은 레이블링을 위해 OTA는 다음과 같은 4개의 레이블링 기법을 제안합니다.
- loss/quality aware
- center prior
- dynamic number of positive anchors
- global view
그러나, Sinkhorn-Knopp 알고리즘을 OT(Optimal Transport)문제에 적용시켰을 경우 25%(300 epochs)의 추가적인 학습시간이 걸리게 되므로 이를 dynamic top-k startegy(named SimOTA)로 정의하게 되었습니다.
SimOTA는 matching degree를 계산하게 되는데 이는 아래와 같은 식으로 계산합니다.
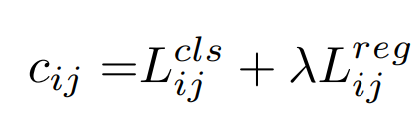
- 여기서
lambda는 불균형을 해소하기 위한 계수이고우변은 GT와 prediction값 사이의 classification loss와 regression loss를 의미합니다. - 이 때, 각각의 GT에 대해 가장 적은 cost값을 갖는 고정된 center region중 top k predictions들을 positives라고 하고 나머지를 모두 negative로 합니다. 이 때, k는 GT에 대해 모두 다른 값을 갖습니다.
- End-to-end YOLO
- one-to-one label assignment와 stop gradient 두개의 conv layer를 추가했지만 이는 성능저하로 이어져 옵션으로 주고 최종 결과물에 포함시키지 않았습니다.
Other Backbones
DarkNet53이외에 다양한 backbones들을 적용시켜보았습니다.
- Modified CSPNet in YOLOv5
- YOLOv5에 적용된 CSPNet, SiLU activation, PAN head를 적용시킨 YOLOX-S,YOLOX-M,YOLOX-X 모델을 비교할 경우 약간의 시간을 trade-off 하여 각각 1~3% AP 향상 효과를 얻게 되었습니다.
- Tiny and Nano detectors
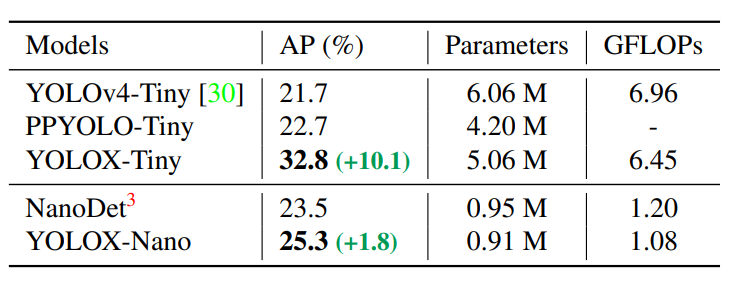
- YOLOv4-Tiny 모델과 비교하기 위해 YOLOX-Tiny모델을 구상하였을 때 아래의 표와 같이 더 나은 성능을 얻게 되었습니다.
- Model size and data augmentation
모든 모델들은 같은 learning schedule과 optimizing parameters들을 갖고 있습니다. 그러나, 모델의 크기별로 다른 적절한 augmentation 기법을 적용시켜야하는 것을 확인했습니다.
예를들어, MixUp과 같은 기법들은 YOLOX-L에서는 0.9% AP상승을 유도했지만 작은모델인 YOLOX-Nano와 같은 모델에는 성능저하를 유도했습니다. 따라서, mosaic 비율을 줄이고 mix up augmentation을 삭제하였습니다.
큰 모델의 경우 stronger augmentation기법이 더 효과적인 것을 확인했습니다. 우리가 새로 구현한 MixUp기법이 기존보다 더 나은 성능을 보장했고 Copypaste기법으로부터 영감을 받아 mix up하기 전에 random sample scale factor를 통해 이미지를 jitter하는 방법을 사용했습니다.
Conclusion
기존의 YOLO 시리즈에 anchor free를 적용시킨 detector를 소개하였습니다. decoupled head, anchor-free, and advanced label assigning strategy를 적용시킨 YOLOX는 속도와 정확도에 더 나은 trade-off를 얻게 되었습니다.