Detection of Abandoned and Stolen Objects Based on Dual Background Model and Mask R-CNN
이번 포스트에서는 CCTV를 이용하여 시스템을 설계하는 팀으로써 유기, 분실, 도난 등의 AI 도입을 위한 최신 논문에 대한 리뷰를 진행해봅니다.
Introduction
최근, surveillance system에 AI기술을 접목시킨 기술이 자주 등장하고 있습니다. 침입, 화재, 배회 등에 대한 대응속도를 최소화 하는데 좋은 기술이 될 것입니다.
그럼에도 불구하고, 전통적인 시스템들은 정확도나 성능측면에서 한계점을 띄고 있었습니다.
하지만, 최근 AI 기술들의 진보는 다양한 응용분야에 좋은 영향력을 끼치고 있습니다.그러므로 이 논문에서는 유기되거나(abandoned) 도난당한(stolen) 물체들을 전통적인(conventional) 배경추출 기술을 통해 background와 foreground를 실시간으로 생성해내고 foreground에서는 유기된 물품을, background에서는 도난당한 물품을 검출하는 시스템을 소개합니다.
또한, 그림자 영역의 경우 foreground에서 유기되거나 도난당한 물품이 아님에도 불구하고 나타나는 경우가 있습니다. 이러한 부분을 개선하고자 합니다.
PROPOSED ALGORITHM FOR DETECTING ABANDONED OBJECT AND STOLEN OBJECT
DUAL BACKGROUND MODEL FOR EXTRACTING STATIONARY OBJECTS

이 논문에서는 특이하게 background subtraction을 두가지 모델로 하였습니다. 한가지는 short-term model, 다른 한가지는 long-term model이라고 하였습니다.
두 가지의 모델로 나눈 이유는 누군가가 잠시 짐을 내려놓았을 때의 예외사항을 방지하기 위해서입니다.
- short-term model
- SB(Short-term Background) : 유기된 물품은 빠르게 SB에 나타난다.
- SF(Short-term Foreground) : 현재 움직이고 있는 객체들이 존재
- Long-term model
- LB(Long-term Background) :
- LF(Long-term Foreground) : 정적인 물체(움직임이 약간이라도 존재하는)가 존재
DF(Difference Foreground) : LF - SF, 정적인 물체들만 존재
단, 이때 일정 임계점 이하의 객체들은 noise라 판단하여 지워진다. 또한, Long-term 과 Short-term을 구분하다보니 당연히 single frame으로는 판단이 불가능하다는 것이 논문의 설명입니다.
위의 dual background subtraction을 통해 우리는 **Stationary Object(정적인 물체)**를 구분할 수 있게 되었습니다. 그렇다면 이제 이 정적인물체를 유기되거나 도난당하거나 그림자영역인지 확인하는 절차가 필요합니다.
ISSUE OF DISCRIMINATION BETWEEN ABANDONED AND STOLEN OBJECT

비록 앞선 dual background model이 정적인 물체를 추출하는 것은 쉽지만 유기된 물품인지 도난당한 물품인지 구분하는 것은 foreground에서 비교하는게 쉽지 않습니다.
DF에 나오는 객체로만 판단을 한다면 1번과 2번예제의 차이점을 구분할 수 없습니다. 하지만, 1번예제는 누군가 놓고간 객체이며 2번예제는 도난당한 객체입니다. 따라서 이를 구분해야합니다.
THE PROPOSED ALGORITHM

이 논문에서 소개한 알고리즘은 다음과 같습니다.
dual background model을 통해 DF에서 정지된 객체를 추출한다. (Candidate Static Object DF : CSO_DF)
- 이때, 일정 크기 이하의 blobs는 노이즈로 처리하여 지운다.
- checking the stability of a blob : blobs들이 반복적으로 같은 위치에 나타날 수 있으므로 연속적인 프레임에서 일정 숫자 이상 나타나면 stable하다고 정의한다.
동시에, Mask R-CNN을 이용하여 현재 프레임에서 object mask를 얻는다. (Segmented Object : SO_VF)
CSO_DF와 SO_VF가 동일한지 확인한다. 동일할 시 이것은 유기된 물품이다.
- 만약 동일하지 않을시
- 이전 LB frames들 중에서 CSO_DF가 background로 흡수되지않은 가장 최근 LB프레임을 추출한다. 이 때, SO_LB가 존재하지 않는다면 유기된 물품이다.
- CSO_LB프레임에서 object segmentation을 진행하여 SO_LB를 추출하여 SO_VF와 비교한다.
- 만약 동일하지 않을시

전체적인 플로우 차트는 위와 같습니다.
이 때, 마스크끼리의 동일성 여부 판단은 다음과 같은 식을 기준으로 합니다.
CSO_DF의 top, left, width, and height는 ‘t’, ‘l’, ‘w’, ‘h’라 할 때, CSO_DF의 mask는 다음과 설정합니다.
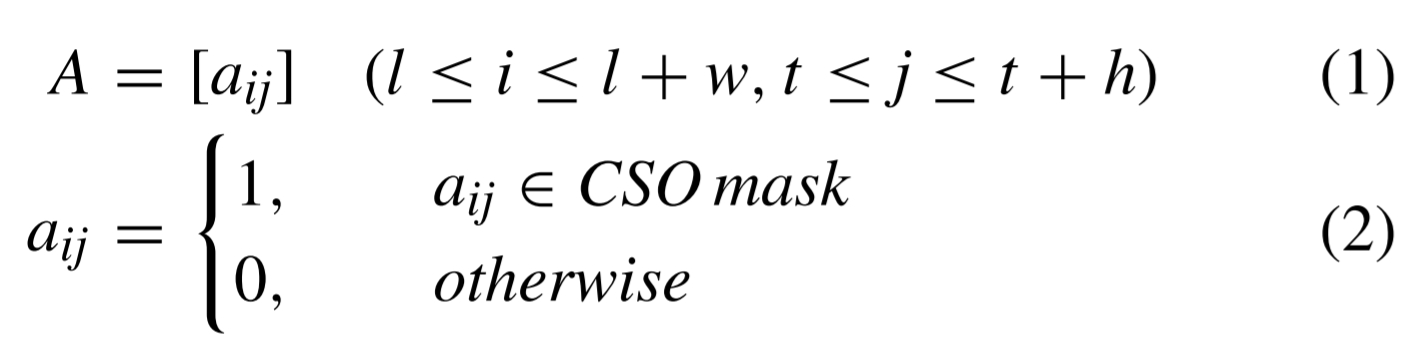
다음으론 Mask R-CNN으로 감지된 mask에 관한 설정입니다.
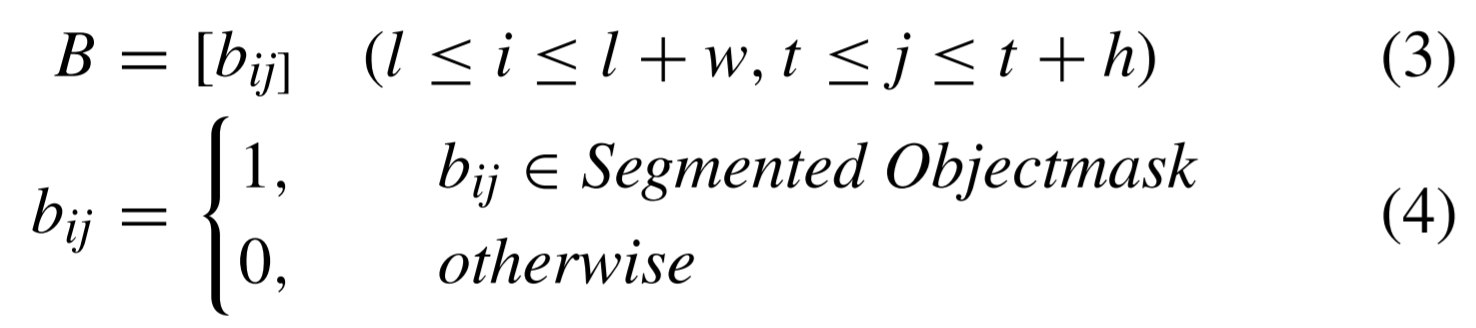
앞선 두 mask의 픽셀값이 동일하면 1, 동일하지 않다면 0으로 set하는 match score mask는 다음과 같이 설정합니다.
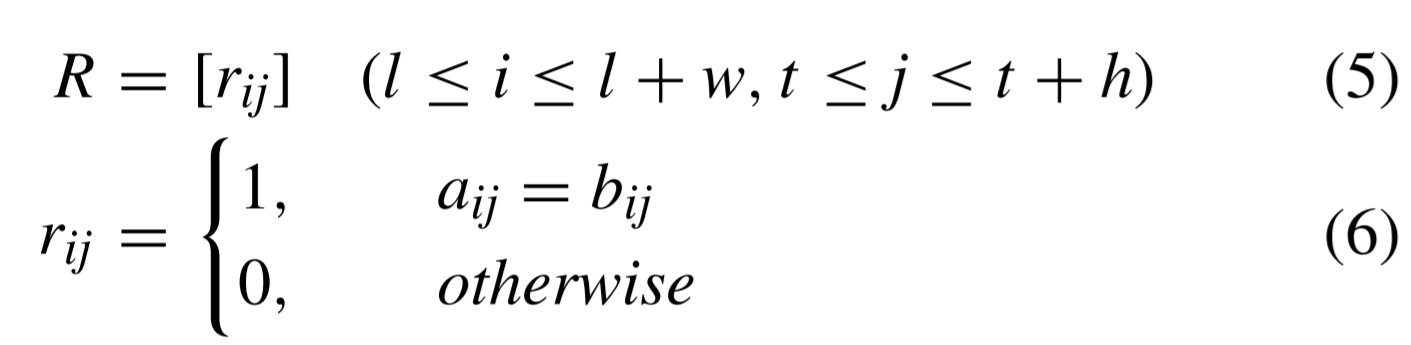
결론적으로 match score는 다음과 같습니다.
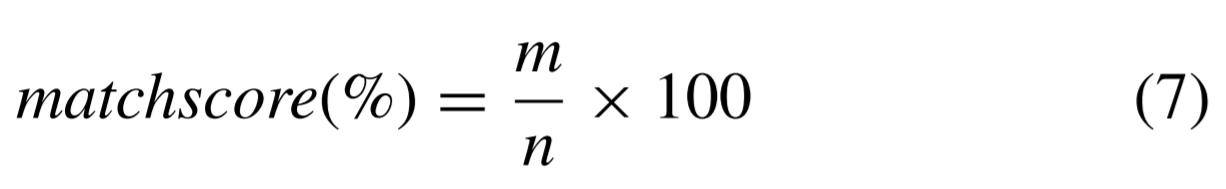
mach score가 일정 threshold보다 높다면 이 둘은 같은 물체이므로
하지만, 다를 경우에는 다음과 같은 경우의 수가 있습니다.
- 둘의 사이즈가 굉장히 다르다. 이는 대개 CSO_DF의 문제일 가능성이 높다. background subtraction은 shadow region과 같은 영역이 foreground에 나타나 실제 CSO_DF에 나타난 물체보다 크게 측정될 수 있기 때문이다.
- 객체가 없을 수도 있다. 과거와 현재에 다른 모양(상태)일 수 있기 때문에 match score는 반드시 CSO_DF의 최종상태로 측정되어야한다.
다음은 그림자영역인지 도난당한 물건인지 유기된 물건인지 구별하는 방법입니다.

구별 방법
- 정적인 물체가 나타난다.(CSO_DF)
- 이전에는 존재하지 않았어야한다.
- stable blob(CSO_DF)영역에 물체가 존재하는지 현재 프레임에서 Mask R-CNN을 이용하여 구별한다.
- 일정 match score보다 높다면 abandoned object이다. ( 위의 (1)의 경우 )
- 일정 match score보다 낮다면 다음의 순서를 따른다.
- 이전 LB frame에서 CSO_DF가 처음으로 생성되는 프레임을 찾는다.
- Mask R-CNN을 이용하여 SO_LB를 찾고, 없다면 이는 abandoned object이다. 왜나하면 ghost region이기 때문이다. ( 위의 (2)의 경우 )
- SO_LB가 있을때,
- SO_VF와 동일하다면 이는 현재 그림자가 생긴것이므로 ghost region이다. ( 위의 (4)의 경우 )
- SO_VF보다 작다면 이는 작은 물체가 존재한 것이므로 abandoned object이다. ( 위의 (3)의 경우)
- SO_VF보다 크다면 이는 과거에 있던 물체가 현재는 사라진 것이므로 stolen object이다. ( 위의 (5), (6)의 경우 )
- SO_LB가 현재일 때, 크기에 관계없이 모두 stolen object이다. ( 위의 (8), (9)의 경우 )
- CSO_DF는 존재하지만 SO_VF도 SO_LF도 생성되지 않는다면 이는 Ghost region이다. ( 위의 (7)의 경우, 아래 예시에서 참조 )

DETERMINING THE FINAL STATE OF A STATIONARY OBJECT (ABANDONED, STOLEN OBJECT, AND GHOST REGION) USING THE DUAL BACKGROUND MODEL AND MASK R-CNN
지금부터는 위에 설명한 시나리오에 대한 예시입니다.
- Stolen object detection when a CSO_DF is identical to a SO_LB, which corresponds to the case of Figure 7-(8).

(4)번에서 DF 프레임에서 CSO_DF가 추출이 가능합니다. 이제 감시시스템은 back-trace를 하게 되는데 현재 SO_VF에는 아무것도 존재하지 않으므로 SO_LB가 현재이므로 이는 stolen object입니다.
- Stolen object detection when a CSO_DF is larger than a SO_LB, which corresponds to the case of Figure 7-(9).

(3)번 DF프레임에서 CSO_DF가 추출이 가능합니다. 마찬가지로 back-trace를 하여 SO_LB가 현재임을 확인할 수 있고 SO_VF에는 아무것도 존재하지 않으므로 이는 stolen object입니다. CSO_DF에는 그림자가 포함되어 SO_LB와 matchscore가 낮지만 이에 관계없이 stolen object로 구별합니다.
- Another example of stolen object detection when a CSO_DF is larger than a SO_LB, which corresponds to the case of Figure 7-(9). And this figure also shows a ghost region detection in the absence of both the SOVF and SOLB, which corresponds to the case of Figure 7-(7).

(3)번 DF프레임에서 CSO_DF가 추출이 가능합니다. 마찬가지로 back-trace를 하여 SO_LB가 현재임을 확인할 수 있고 SO_VF에는 아무것도 존재하지 않으므로 이는 stolen object입니다. 빛의 방향에 따라 ghost region이 foreground에 포함되어 나타나는 것을 확인할 수 있지만 이는 모두 SO_VF와 SO_LB에 나타나지 않으므로 ghost region으로 분류가 가능해집니다.
- Stolen object detection when a CSO_DF does not match a SO_VF and the SO_VF is smaller than a SO_LB, which corresponds to the case of Figure 7-(6).

(4)번 DF프레임에서 CSO_DF가 추출이 가능합니다. 다시 back-trace를 하는데 SO_LB가 SO_VF보다 크므로 원래 있던 물체 뒤에 있는 물체이거나 훔친사람이 작은 물건을 대체해 놓은 것이므로 도난상태가 될 것입니다.
Conclusion
기존 CCTV 감시 시스템은 버려진 물체가 훔친 물건 혹은 Ghost region을 오탐하는 경우가 많았습니다. 따라서, 위의 세가지 사례를 정확히 구분하는 알고리즘을 제시하였습니다.
CSO_DF, SO_VF, SO_LB와 같은 영역에 대한 비교분석 결과에 따라 배경제거영상에서 후보 객체들을 정확히 구분할 수 있게 되었습니다.
현재 회사에서 CCTV로 유기물체를 검출하는 알고리즘을 설계중에 있습니다. 위의 기술된 Mask R-CNN의 경우 실시간이라고 하기엔 부족한 FPS를 가지고 있으므로 적합하지 않은 CNN 모델이라고 생각합니다. 하지만, YOLO 모델을 이용할 경우 훨씬 나은 성능을 보여주고 있습니다.
Reference
Detection of Abandoned and Stolen Objects Based on Dual Background Model and Mask R-CNN