[AAIS] E04. Transfer Learning - 1
Transfer Learning
About VGG16 https://analysisbugs.tistory.com/65?category=839091 https://bskyvision.com/504 https://medium.com/@msmapark2/vgg16-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-very-deep-convolutional-networks-for-large-scale-image-recognition-6f748235242a
이전의 모델들은 대부분 7x7 filter, 11x11 filter를 사용하였으나 이부분부터 3x3 filter를 사용하였습니다.
예시로 10x10을 7x7 filter를 통과시키면 feature map이 4x4가 만들어지는데 필요한 파라미터 수는 7x7 = 49이고
Q.이렇게 할 경우 왜 좋은가? : 3x3일경우 패딩이 1이라서 경계선의 추론이 더 쉬워진다? + relu를 세번통과하기 때문에 비 선형성이 증가하게 된다.
transfer learning
모델을 가져와서 ‘include_top=False’를 통해 분류층(classification)을 삭제시킨다.
‘model.trainable = False’로 설정시켜서 동결(freezing)을 시킨다.
global_average_pooling과 dense layer를 쌓은 후 컴파일한다.
ImageDataGenerator를 통해 적은량의 데이터를 data augmentation을 진행시킨 후 학습시킨다.
‘model.trainable = True’로 설정시켜서 동결을 해제한다.
learning_rate을 매우 낮게 설정하여 fine-tuning하기
Mon Jan 25 13:30:28 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-DGXS... On | 00000000:07:00.0 Off | 0 |
| N/A 41C P0 49W / 300W | 947MiB / 32478MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-DGXS... On | 00000000:08:00.0 Off | 0 |
| N/A 39C P0 40W / 300W | 12MiB / 32478MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-DGXS... On | 00000000:0E:00.0 Off | 0 |
| N/A 40C P0 52W / 300W | 5134MiB / 32478MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-DGXS... On | 00000000:0F:00.0 Off | 0 |
| N/A 39C P0 38W / 300W | 38MiB / 32478MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+1. classification층을 삭제
1 keras.application.VGG16(weights,input_shape,include_top)
include_top은 최상단 Layer인 fully connected layer를 포함시키는지 여부를 전달시키는 것으로 pre-trained된 것을 새롭게 prediction하기위해 이 layer는 제거시켜줍니다.
1 2 3 4 5 6 from tensorflow import kerasbase_model = keras.applications.VGG16( weights='imagenet' , input_shape=(224 , 224 , 3 ), include_top=False )
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________이전과 다르게 classification layer이 삭제되었다. (Flatten ~ Dense)
1 base_model.trainable = False
2. 기존의 네트워크 동결시키기 trainable옵션을 False로 하여 새로운 학습을 할 때에 기존의 학습된 네트워크가 같이 학습되지 않도록 합니다.
1 2 3 4 5 6 7 8 inputs = keras.Input(shape=(224 , 224 , 3 )) x = base_model(inputs, training=False ) x = keras.layers.GlobalAveragePooling2D()(x) outputs = keras.layers.Dense(1 )(x) model = keras.Model(inputs, outputs) model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
vgg16 (Model) (None, 7, 7, 512) 14714688
_________________________________________________________________
global_average_pooling2d (Gl (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 1) 513
=================================================================
Total params: 14,715,201
Trainable params: 513
Non-trainable params: 14,714,688
_________________________________________________________________about layer
GlobalAveragePooing2D
기존의 fully convolutional Network는 많은 parameter수와 계산이 오래걸리고, 위치의 정보가 모두 사라지는 단점이 있습니다.
같은 chennel의 feature들의 평균을 내어 채널의 개수만큼 원소를 가지는 벡터를 출력 (이경우에는 입력 층이 (7,7,512)이므로 (512,)를 출력시키는 layer)
fully connected layer를 없애기 위한 방법
코드
Dense(1)
binary로 클래스를 분류할 것이기 때문에 0과 1로 classification
1 2 model.compile (loss=keras.losses.BinaryCrossentropy(from_logits=True ), metrics=[keras.metrics.BinaryAccuracy()])
before data augmentation
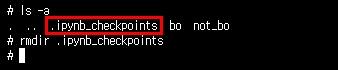
위 그림과같이 ImageDataGenerator.flow_from_directory를 사용할 때에 hidden folder가 있는지 확인해야합니다.
1 2 3 4 5 6 7 dog test bo not_bo train bo not_bo
위와 같이 directory별로 class를 구분하기 때문에 .ipynb_checkpoints폴더를 삭제해야합니다.
1 2 3 4 5 6 7 8 9 10 from tensorflow.keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator( samplewise_center=True , rotation_range=10 , zoom_range = 0.1 , width_shift_range=0.1 , height_shift_range=0.1 , horizontal_flip=True , vertical_flip=False )
data augmentation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 seed = 1 train_it = datagen.flow_from_directory('../sungjin/dog/train/' , seed = seed, target_size=(224 , 224 ), color_mode='rgb' , class_mode='binary' , batch_size=8 ) test_it = datagen.flow_from_directory('../sungjin/dog/test/' , seed = seed, target_size=(224 , 224 ), color_mode='rgb' , class_mode='binary' , batch_size=8 )
Found 139 images belonging to 2 classes.
Found 20 images belonging to 2 classes.1 history = model.fit(train_it, steps_per_epoch=12 , validation_data=test_it, validation_steps=4 , epochs=20 )
Epoch 1/20
12/12 [==============================] - 3s 225ms/step - loss: 1.4831 - binary_accuracy: 0.6562 - val_loss: 3.5233 - val_binary_accuracy: 0.5357
Epoch 2/20
12/12 [==============================] - 2s 178ms/step - loss: 1.1998 - binary_accuracy: 0.7473 - val_loss: 1.9760 - val_binary_accuracy: 0.6667
Epoch 3/20
12/12 [==============================] - 2s 161ms/step - loss: 0.4746 - binary_accuracy: 0.8462 - val_loss: 1.3999 - val_binary_accuracy: 0.7143
Epoch 4/20
12/12 [==============================] - 2s 172ms/step - loss: 0.3132 - binary_accuracy: 0.8646 - val_loss: 1.0363 - val_binary_accuracy: 0.7857
Epoch 5/20
12/12 [==============================] - 2s 175ms/step - loss: 0.2785 - binary_accuracy: 0.9011 - val_loss: 1.0750 - val_binary_accuracy: 0.7917
Epoch 6/20
12/12 [==============================] - 2s 178ms/step - loss: 0.0651 - binary_accuracy: 0.9670 - val_loss: 1.3541 - val_binary_accuracy: 0.7143
Epoch 7/20
12/12 [==============================] - 2s 198ms/step - loss: 0.1798 - binary_accuracy: 0.9167 - val_loss: 0.9755 - val_binary_accuracy: 0.8214
Epoch 8/20
12/12 [==============================] - 2s 166ms/step - loss: 0.0315 - binary_accuracy: 0.9890 - val_loss: 0.5196 - val_binary_accuracy: 0.9167
Epoch 9/20
12/12 [==============================] - 2s 179ms/step - loss: 0.0822 - binary_accuracy: 0.9341 - val_loss: 0.3601 - val_binary_accuracy: 0.8929
Epoch 10/20
12/12 [==============================] - 2s 181ms/step - loss: 0.0169 - binary_accuracy: 0.9896 - val_loss: 0.3563 - val_binary_accuracy: 0.9286
Epoch 11/20
12/12 [==============================] - 2s 191ms/step - loss: 0.0437 - binary_accuracy: 0.9890 - val_loss: 0.4602 - val_binary_accuracy: 0.8333
Epoch 12/20
12/12 [==============================] - 2s 158ms/step - loss: 0.0405 - binary_accuracy: 0.9890 - val_loss: 0.2497 - val_binary_accuracy: 0.8929
Epoch 13/20
12/12 [==============================] - 2s 191ms/step - loss: 0.0083 - binary_accuracy: 1.0000 - val_loss: 0.4642 - val_binary_accuracy: 0.8571
Epoch 14/20
12/12 [==============================] - 2s 163ms/step - loss: 0.0133 - binary_accuracy: 0.9890 - val_loss: 0.2259 - val_binary_accuracy: 0.9167
Epoch 15/20
12/12 [==============================] - 2s 178ms/step - loss: 0.0050 - binary_accuracy: 1.0000 - val_loss: 0.2705 - val_binary_accuracy: 0.8929
Epoch 16/20
12/12 [==============================] - 2s 185ms/step - loss: 0.0027 - binary_accuracy: 1.0000 - val_loss: 0.2617 - val_binary_accuracy: 0.8929
Epoch 17/20
12/12 [==============================] - 2s 179ms/step - loss: 0.0203 - binary_accuracy: 0.9890 - val_loss: 0.1751 - val_binary_accuracy: 0.9583
Epoch 18/20
12/12 [==============================] - 2s 173ms/step - loss: 0.0055 - binary_accuracy: 1.0000 - val_loss: 0.0705 - val_binary_accuracy: 1.0000
Epoch 19/20
12/12 [==============================] - 2s 199ms/step - loss: 0.0015 - binary_accuracy: 1.0000 - val_loss: 0.0275 - val_binary_accuracy: 1.0000
Epoch 20/20
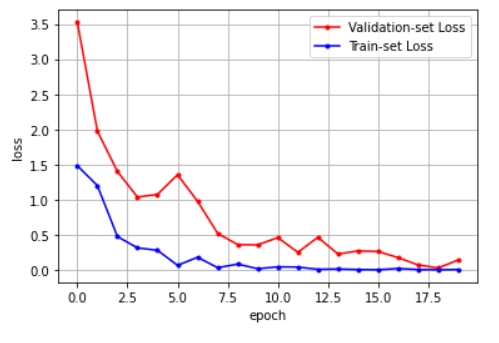
12/12 [==============================] - 2s 189ms/step - loss: 0.0056 - binary_accuracy: 1.0000 - val_loss: 0.1403 - val_binary_accuracy: 0.9583기존의 네트워크 동결 해제 및 fine-tuning 새롭게 컴파일할 때 기존의 네트워크를 unfreezing하여 fine-tuning(미세조정)한다.
전체모델을 학습시키기
이 방법은 pre-trained model의 구조만 사용하고 새로운 데이터셋에 맞게 전부 새로 학습시키는 방법입니다. 큰 사이즈의 데이터셋이 필요합니다.
일부의 층만 학습시키고 나머지는 동결시키기
초기 레이어는 추상적인(일반적인)특징을 추출하고 후기 레이어는 구체적이고 특유한 특징을 추출하는데 이런 특성을 이용해서 선택적으로 재학습시킵니다.
데이터셋이 작고 모델의 파라미터가 많다면 오버피팅이 될 수 있으므로 적은양의 계층을 학습시킵니다.
데이터셋이 크고 그에 비해 모델의 파라미터가 적다면 오버피팅의 가능성이 적으므로 더 많은 양의 계층을 학습시킵니다.
전체 동결시키기 (classification만 학습시키기)
기존의 네트워크는 건들지 않고 그대로 두면서 특징 추출 메커니즘으로써 활용하고, classifier만 재학습시키는 방법을 씁니다.
데이터셋이 너무 작을때나 새로운 문제가 이전 모델이 이미 학습한 데이터셋과 매우 비슷할 때 사용합니다.
1 2 3 4 5 6 7 8 9 10 base_model.trainable = True model.compile (optimizer = keras.optimizers.Adam(lr = .00001 ), loss=keras.losses.BinaryCrossentropy(from_logits=True ), metrics=[keras.metrics.BinaryAccuracy()])
reference
1 history = model.fit(train_it, steps_per_epoch=12 , validation_data=test_it, validation_steps=4 , epochs=20 )
Epoch 1/20
12/12 [==============================] - 3s 219ms/step - loss: 0.0849 - binary_accuracy: 0.9670 - val_loss: 0.0158 - val_binary_accuracy: 1.0000
Epoch 2/20
12/12 [==============================] - 2s 204ms/step - loss: 0.0053 - binary_accuracy: 1.0000 - val_loss: 0.0118 - val_binary_accuracy: 1.0000
Epoch 3/20
12/12 [==============================] - 2s 176ms/step - loss: 0.0020 - binary_accuracy: 1.0000 - val_loss: 0.0015 - val_binary_accuracy: 1.0000
Epoch 4/20
12/12 [==============================] - 2s 196ms/step - loss: 1.5012e-04 - binary_accuracy: 1.0000 - val_loss: 0.0154 - val_binary_accuracy: 1.0000
Epoch 5/20
12/12 [==============================] - 3s 211ms/step - loss: 1.7610e-04 - binary_accuracy: 1.0000 - val_loss: 0.0034 - val_binary_accuracy: 1.0000
Epoch 6/20
12/12 [==============================] - 2s 198ms/step - loss: 1.0886e-04 - binary_accuracy: 1.0000 - val_loss: 0.0275 - val_binary_accuracy: 1.0000
Epoch 7/20
12/12 [==============================] - 2s 178ms/step - loss: 2.9665e-05 - binary_accuracy: 1.0000 - val_loss: 0.0093 - val_binary_accuracy: 1.0000
Epoch 8/20
12/12 [==============================] - 2s 205ms/step - loss: 1.7676e-05 - binary_accuracy: 1.0000 - val_loss: 0.0108 - val_binary_accuracy: 1.0000
Epoch 9/20
12/12 [==============================] - 2s 182ms/step - loss: 3.1658e-05 - binary_accuracy: 1.0000 - val_loss: 8.7812e-04 - val_binary_accuracy: 1.0000
Epoch 10/20
12/12 [==============================] - 2s 195ms/step - loss: 3.5808e-05 - binary_accuracy: 1.0000 - val_loss: 0.0020 - val_binary_accuracy: 1.0000
Epoch 11/20
12/12 [==============================] - 2s 191ms/step - loss: 3.2332e-05 - binary_accuracy: 1.0000 - val_loss: 0.0474 - val_binary_accuracy: 0.9643
Epoch 12/20
12/12 [==============================] - 2s 202ms/step - loss: 1.3189e-04 - binary_accuracy: 1.0000 - val_loss: 0.0044 - val_binary_accuracy: 1.0000
Epoch 13/20
12/12 [==============================] - 2s 202ms/step - loss: 1.7362e-04 - binary_accuracy: 1.0000 - val_loss: 0.0073 - val_binary_accuracy: 1.0000
Epoch 14/20
12/12 [==============================] - 2s 194ms/step - loss: 2.4271e-05 - binary_accuracy: 1.0000 - val_loss: 0.0235 - val_binary_accuracy: 1.0000
Epoch 15/20
12/12 [==============================] - 3s 219ms/step - loss: 1.0316e-05 - binary_accuracy: 1.0000 - val_loss: 0.0388 - val_binary_accuracy: 1.0000
Epoch 16/20
12/12 [==============================] - 2s 187ms/step - loss: 2.3622e-05 - binary_accuracy: 1.0000 - val_loss: 0.0031 - val_binary_accuracy: 1.0000
Epoch 17/20
12/12 [==============================] - 2s 201ms/step - loss: 2.0185e-05 - binary_accuracy: 1.0000 - val_loss: 0.0413 - val_binary_accuracy: 0.9643
Epoch 18/20
12/12 [==============================] - 2s 175ms/step - loss: 3.8968e-05 - binary_accuracy: 1.0000 - val_loss: 0.0197 - val_binary_accuracy: 1.0000
Epoch 19/20
12/12 [==============================] - 2s 202ms/step - loss: 9.7374e-06 - binary_accuracy: 1.0000 - val_loss: 0.0902 - val_binary_accuracy: 0.9643
Epoch 20/20
12/12 [==============================] - 2s 206ms/step - loss: 1.0378e-04 - binary_accuracy: 1.0000 - val_loss: 0.0148 - val_binary_accuracy: 1.00001 2 3 4 5 6 7 8 9 inputs = keras.Input(shape=(224 , 224 , 3 )) x = base_model(inputs, training=False ) x = keras.layers.Flatten(input_shape=(7 ,7 ,512 ))(x) outputs = keras.layers.Dense(1 ,activation = 'sigmoid' )(x) model = keras.Model(inputs, outputs) model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
vgg16 (Model) (None, 7, 7, 512) 14714688
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 1) 25089
=================================================================
Total params: 14,739,777
Trainable params: 25,089
Non-trainable params: 14,714,688
_________________________________________________________________1 2 3 4 5 model.compile ( loss=keras.losses.BinaryCrossentropy(from_logits=True ), metrics=[keras.metrics.BinaryAccuracy()])
1 2 3 4 5 6 7 8 9 10 from tensorflow.keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator( samplewise_center=True , rotation_range=10 , zoom_range = 0.1 , width_shift_range=0.1 , height_shift_range=0.1 , horizontal_flip=True , vertical_flip=False )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 seed = 1 train_it = datagen.flow_from_directory('../sungjin/dog/train/' , seed = seed, target_size=(224 , 224 ), color_mode='rgb' , class_mode='binary' , batch_size=8 ) test_it = datagen.flow_from_directory('../sungjin/dog/test/' , seed = seed, target_size=(224 , 224 ), color_mode='rgb' , class_mode='binary' , batch_size=8 )
Found 139 images belonging to 2 classes.
Found 20 images belonging to 2 classes.1 history = model.fit(train_it, steps_per_epoch=12 , validation_data=test_it, validation_steps=4 , epochs=20 )
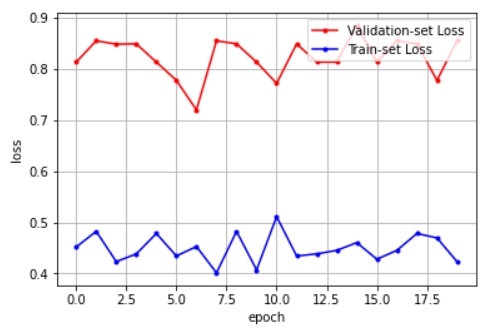
Epoch 1/20
12/12 [==============================] - 3s 243ms/step - loss: 0.4516 - binary_accuracy: 0.8333 - val_loss: 0.8132 - val_binary_accuracy: 0.5000
Epoch 2/20
12/12 [==============================] - 2s 195ms/step - loss: 0.4823 - binary_accuracy: 0.8352 - val_loss: 0.8549 - val_binary_accuracy: 0.4583
Epoch 3/20
12/12 [==============================] - 2s 179ms/step - loss: 0.4232 - binary_accuracy: 0.8901 - val_loss: 0.8483 - val_binary_accuracy: 0.4643
Epoch 4/20
12/12 [==============================] - 2s 202ms/step - loss: 0.4383 - binary_accuracy: 0.8750 - val_loss: 0.8490 - val_binary_accuracy: 0.4643
Epoch 5/20
12/12 [==============================] - 2s 195ms/step - loss: 0.4781 - binary_accuracy: 0.8352 - val_loss: 0.8133 - val_binary_accuracy: 0.5000
Epoch 6/20
12/12 [==============================] - 2s 199ms/step - loss: 0.4341 - binary_accuracy: 0.8791 - val_loss: 0.7775 - val_binary_accuracy: 0.5357
Epoch 7/20
12/12 [==============================] - 2s 204ms/step - loss: 0.4526 - binary_accuracy: 0.8646 - val_loss: 0.7197 - val_binary_accuracy: 0.6071
Epoch 8/20
12/12 [==============================] - 2s 170ms/step - loss: 0.4012 - binary_accuracy: 0.9121 - val_loss: 0.8549 - val_binary_accuracy: 0.4583
Epoch 9/20
12/12 [==============================] - 2s 197ms/step - loss: 0.4823 - binary_accuracy: 0.8352 - val_loss: 0.8490 - val_binary_accuracy: 0.4643
Epoch 10/20
12/12 [==============================] - 2s 201ms/step - loss: 0.4070 - binary_accuracy: 0.9062 - val_loss: 0.8133 - val_binary_accuracy: 0.5000
Epoch 11/20
12/12 [==============================] - 2s 205ms/step - loss: 0.5111 - binary_accuracy: 0.8022 - val_loss: 0.7716 - val_binary_accuracy: 0.5417
Epoch 12/20
12/12 [==============================] - 2s 181ms/step - loss: 0.4341 - binary_accuracy: 0.8791 - val_loss: 0.8490 - val_binary_accuracy: 0.4643
Epoch 13/20
12/12 [==============================] - 3s 216ms/step - loss: 0.4383 - binary_accuracy: 0.8750 - val_loss: 0.8133 - val_binary_accuracy: 0.5000
Epoch 14/20
12/12 [==============================] - 2s 190ms/step - loss: 0.4451 - binary_accuracy: 0.8681 - val_loss: 0.8133 - val_binary_accuracy: 0.5000
Epoch 15/20
12/12 [==============================] - 2s 191ms/step - loss: 0.4603 - binary_accuracy: 0.8571 - val_loss: 0.8847 - val_binary_accuracy: 0.4286
Epoch 16/20
12/12 [==============================] - 2s 202ms/step - loss: 0.4278 - binary_accuracy: 0.8854 - val_loss: 0.8133 - val_binary_accuracy: 0.5000
Epoch 17/20
12/12 [==============================] - 2s 205ms/step - loss: 0.4451 - binary_accuracy: 0.8681 - val_loss: 0.8549 - val_binary_accuracy: 0.4583
Epoch 18/20
12/12 [==============================] - 2s 179ms/step - loss: 0.4781 - binary_accuracy: 0.8352 - val_loss: 0.8490 - val_binary_accuracy: 0.4643
Epoch 19/20
12/12 [==============================] - 2s 207ms/step - loss: 0.4695 - binary_accuracy: 0.8438 - val_loss: 0.7775 - val_binary_accuracy: 0.5357
Epoch 20/20
12/12 [==============================] - 2s 185ms/step - loss: 0.4232 - binary_accuracy: 0.8901 - val_loss: 0.8549 - val_binary_accuracy: 0.4583Global Average Pooing vs Fully Convolutional Network