Agian CNN
Review the reports
Tooth-wise age-group prediction with CNN model
1 | Tooth‑wise age‑group prediction with CNN model. As the frst molar is considered to be the most reliable tooth for estimating dental age, we selected it for developing a CNN model for the age-group determination. |
첫번째 큰어금니가 치아 나이를 추론12하는데 가장 좋으므로, 이를 채택하여 CNN 모델을 생성하였다.
각각의 환자의 파노라마사진으로부터 #16, #26, #36, #46번 치아를 추출하였다.
파노라마 이미지로부터 image patch를 추출하는 목표는 완전한 이의 윤곽(contour)를 포함시키는 것이다. 결론적으로, 1078명의 이미지로부터 4,312개의 image patch들을 모았고 모든 image patch는 151 X 112로 사이즈를 리사이징(resize)하였다. 불필요한 데이터셋들을 줄이고 모델의 성능(performance)를 증가시키기위해 데이터셋이 추가3되었다.
ResNet-1523(The Residual deep neural network with 152 layers)는 각각의 치아의 age-group을 추정했다. 가중치(The weights of the network)는 ImageNet datet으로부터 이미 훈련된것들로부터 시작되었다. 그 후, 전체 네트워크는 age-group을 추정하기위한 모델로 변형(fine-tuned)되었다. 비록, ImageNetbase dataset은 이(teeth)의 이미지를 포함하지 않지만, 다수의 연구들이 의학이미지(medical image)들을 사용하여 질병에관련된 문제들을 푸는데 성능을 증가시켰다는 것을 보여줬다. ResNet은 cross-entopy loss function과 adaptive moment estimation(Adam) optimizer를 통해 학습되었다. learning rate은 1e-5이며 batch size는 32이다. 또한, 4만번의 반복학습을 하였고 1000회마다 분류(classification)정확도를 측정하였다. 가장 높은 validation accuracy를 보여준 네트워크를 최종모델로 선정하였다.
ResNet-152?
위의 내용에 따르면 ResNet-152라는 것이 나온다. CNN이랑 다른건가?싶어 걱정이 앞섰지만 다행히도 CNN의 한 종류이다.
Deep Residual Learning for Image Recognition에 따르면 residual learning을 통해 기존의 심층신경망보다 상당히 깊은 신경망에 대해서도 학습을 잘하고 있는 것을 보여준다. 152개의 layer로 구성되어있으며, 전년도 ILSVRC에서 우승한 GoogleLeNet보다 약 두배의 성능이 좋아졌다.

위 그림을 보면 레이어가 점점 깊어지는데 error_rate이 줄어드는 것을 확인할 수 있다. 그렇다면 레이어가 깊어질수록 더 좋은 결과를 보여주는 것이 아닌가?생각이 들 수 있다. 하지만, 앞선 포스트에서도 확인했듯이 CNN의 layer가 많아질수록(깊어질수록) 파라미터의 수가 급격히 늘어남을 확인했었다. 이는 overfitting의 문제가 아닐지라도 에러가 커지는 현상이 발생하게 된다. 무조건적으로 layer를 깊게하는 것이 아닌 다른 방법이 필요하다 생각한 것이고 residual learning을 하게 된 것이다.
따라서, ResNet팀은 두가지의 원칙을 세웠다고 한다.
- 출력 feature-map의 크기가 같은 경우, 해당 모든 layer는 모두 동일한 수의 filter를 갖는다.
- feature-map의 크기가 절반으로 작아지는 경우는 연산량의 균형을 맞추기 위해 필터의 수를 두배로 늘린다. Feature-map의 크기를 줄일 때는 pooling을 사용하는 대신에 convolution을 수행할 때, stride의 크기를 “2”로 하는 방식을 취한다.
연산량에 대해서는 자세히 배운 후 다시 다뤄보도록 하겠다. 우선, maxpooling과 dropout이 이 네트워크에선 쓰이지 않았다고 한다. 쓰이지 않은 이유를 알기 전에 먼저 maxpooling과 dropout을 알아보겠다.
maxpooling2d
convolution layer의 출력 이미지에서 주요값만 뽑아 크기가 작은 출력영상으로 만드는 역할이다. 이 layer는 사소한 변화가 영향을 미치지 않도록 한다.
1 | MaxPooling2D(pool_size = (2,2)) |
pool_size가 (2,2)이면 입력영상의 크기가 절반으로 줄어든다.
예를 들어, input_shape이 4X4 이고, pool_size가 2,2일 때를 도식화 하면 다음과 같다. 녹색은 입력영상을, 노란색은 pool_size에 따라 나눈 경계를, pool마다 가장 큰값(max)을 선택하여 파란블럭으로 만들면, 그것이 output이 된다.
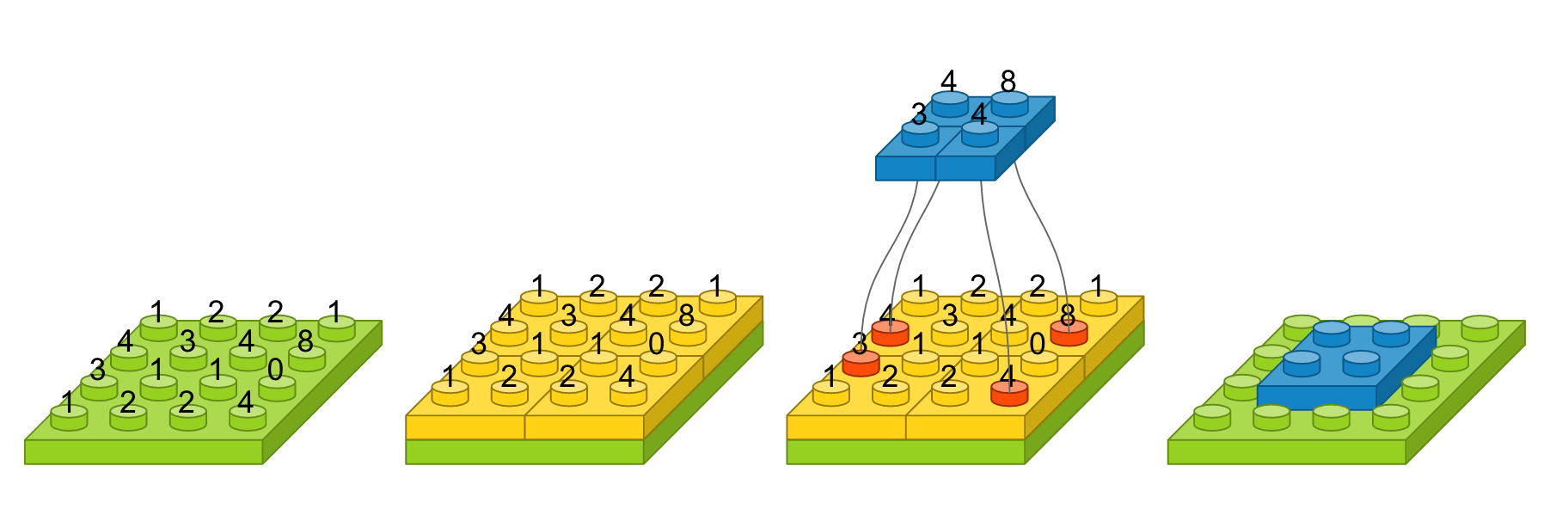
이것이 translation에 굉장히 좋은 결과를 얻게되는데 그 이유는 밑의 그림을 통해 한눈에 알아볼 수 있다.
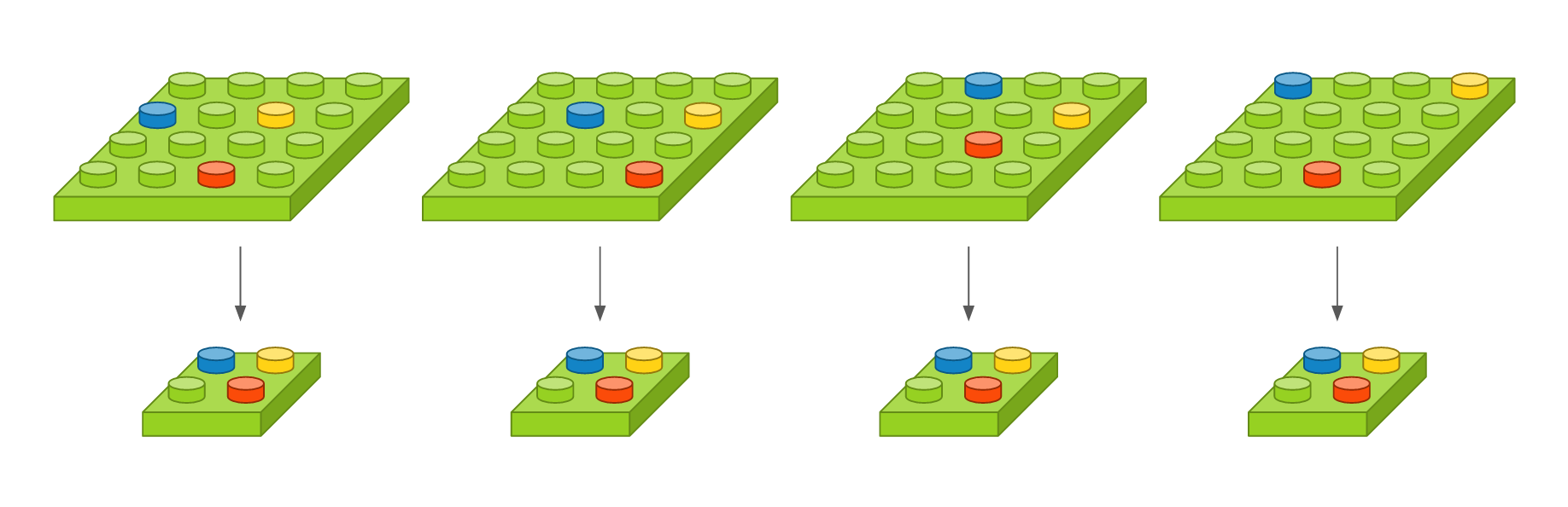
결론적으로 분류 작업에 유리한 불변성질(invariance)를 얻을 수 있는 장점도 있다.
하지만 ResNet-152에서는 maxpooling을 가급적 사용하지 않았다(except 1 layer). maxpooling은 이미지 구성요소의 공간관계에 대한 정보를 잃기 때문이다. 이는 위치와 상관없이 객체를 동일하게 인식하지만, 방향(orientation)이나 비율(proportion)이 달라지면 서로 다른 객체로 인식하게 된다. 특히 시점(viewpoint)변화에 유독 취약하다. 이를 해결하기 위해 data augmentation을 사용하지만 학습시간이 증가하게 되는 단점이 생기게 된다.
제프리 힌턴교수는 CNN의 층을 쌓는 대신, 캡슐망을 고안해냈는데 이는 나의 범위를 넘어가므로 먼훗날.. 다시 다뤄보겠다.
dropout
1 | Dropout(0.2) |
layer가 많아질 때 대표적으로 발생하는 문제는 overfitting이다. 아래 그림처럼 unseparable한 상황임에도 불구하고 억지로 separate하는 상황을 overfitting이라고 한다.
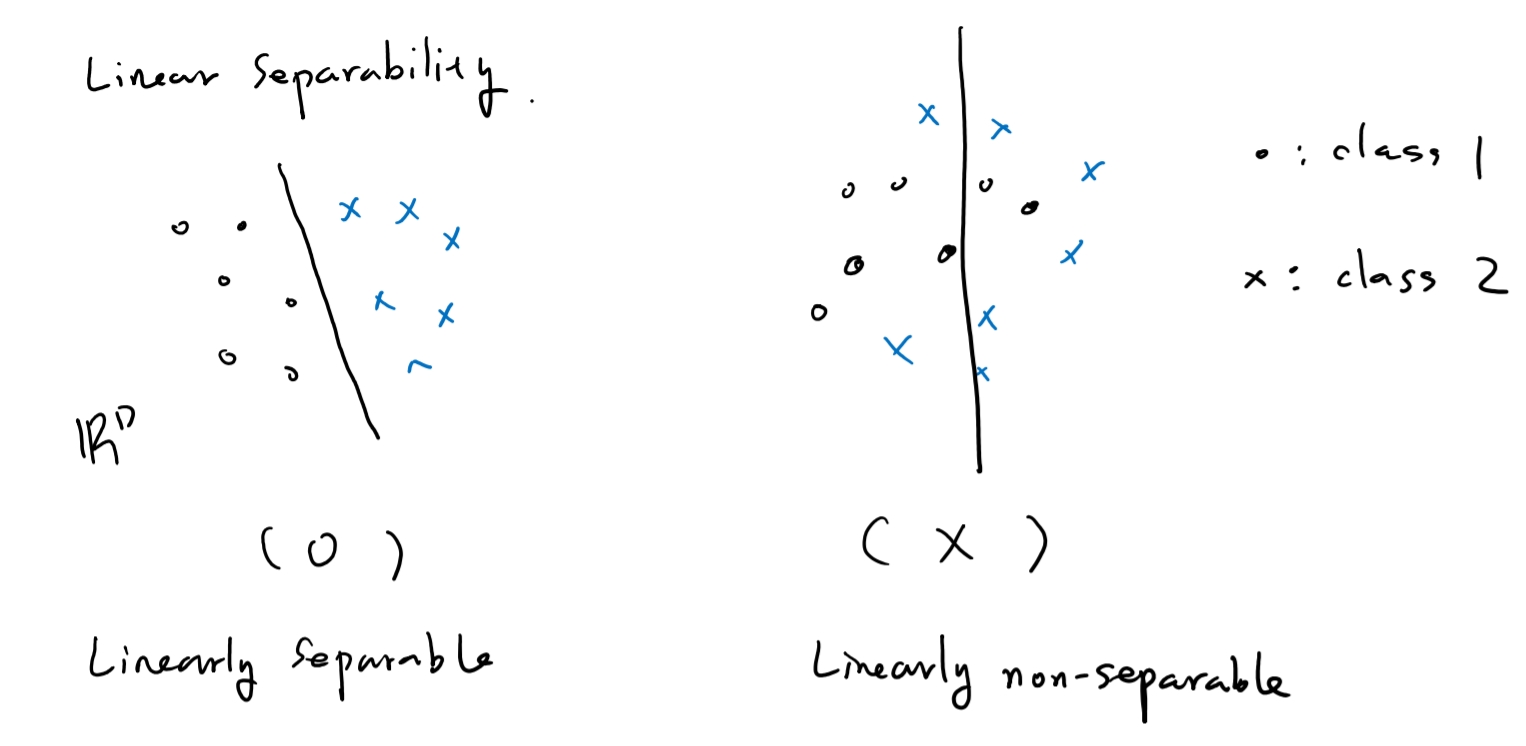
overfitting을 방지하는 방법은 세가지가 있다고 한다.
- training data를 늘리기
- feature의 수를 줄이기
- regularization

이 중 Dropout은 regularization에 해당한다. reLU도 이에 해당한다. Dropout은 일부 neuron을 제거하여 다음 학습에 필요하지 않도록 만드는 것이다. 그렇다면 이게 왜 좋은 방법인 것인가?
“사공이 많으면 배가 산으로간다”라고 생각하면 좋다. 고양이임을 판단할 때 귀,꼬리,발톱,손,눈 등을 판단하는 여러 weight이 있다고 생각할 때, dropout을 통해 몇개의 노드들을 쉬게하는 것이다.
위의 예제에서는 20퍼센트의 neuron들을 쉬게하는것이다. 노드들의 정보는 남기고 connection만 삭제하는 dropconnect같은 방법도 있다고 한다.
위의 오버피팅을 줄이기 위해서 ensenble이라는 방법을 사용한다고 한다. 이는 ResNet-152에서도 사용했다고 하는데 2~5%정도의 예측률이 올라간다고 한다. 이또한 나중에 다뤄보겠다.
Reference
https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
https://www.kakaobrain.com/blog/9
http://blog.creation.net/mxnet-part-5-vgc16-resnet152
https://doorbw.tistory.com/147
https://pythonkim.tistory.com/42
1 : Shah, P. H. & Venkatesh, R. Pulp/tooth ratio of mandibular frst and second molars on panoramic radiographs: an aid for forensic
age estimation. J. Forensic Dent. Sci. 8, 112. https://doi.org/10.4103/0975-1475.186374 (2016).
2 : Mathew, D. G. et al. Adult forensic age estimation using mandibular frst molar radiographs: a novel technique. J. Forensic Dent. Sci. 5, 56–59. https://doi.org/10.4103/0975-1475.114552 (2013).
3 : He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, 770–778, https://doi.org/10.1109/CVPR.2016.90.