Conv2D Layer
이번 포스트에서는 Conv2D Layer에 대해서 자세히 다뤄볼 예정이다.
Conv2D parameters
1 | tf.keras.layers.Conv2D( |
filters: convolution filter의 수
1 | Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 1)) |
이 코드를 도식화 하면 다음과 같다.
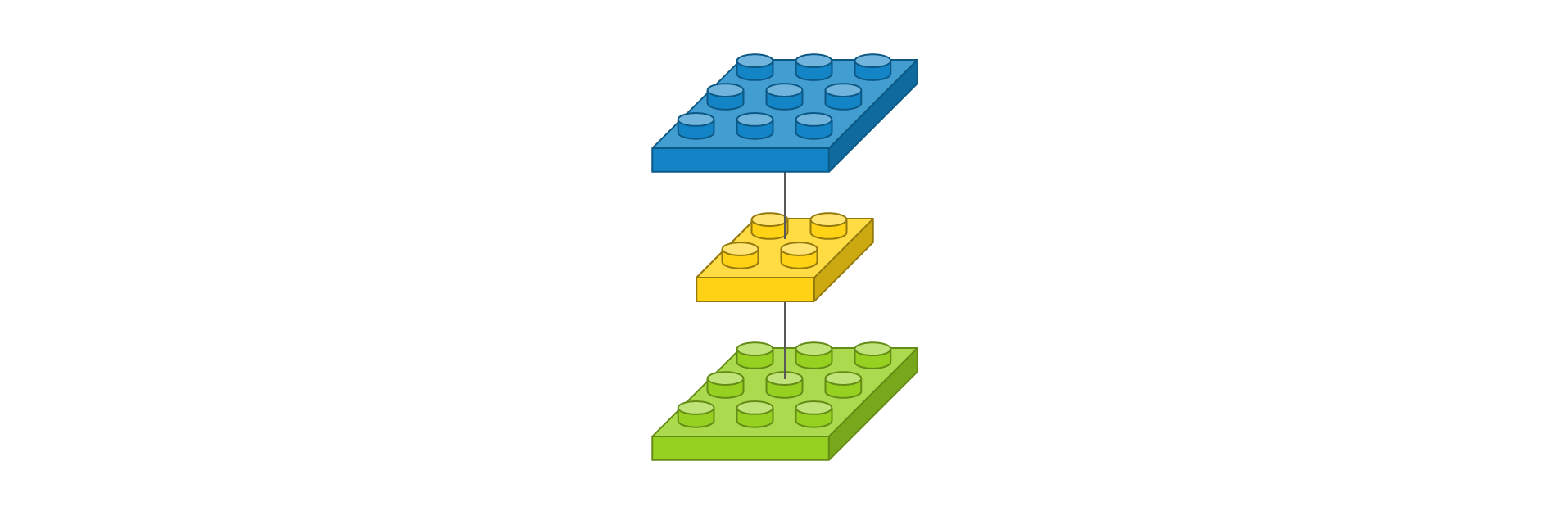
필터의 개수가 채널의 수와도 연관이 있으므로 input_shape을 고려해서 필터의 개수를 지정해야 한다. 이 필터를 거치게 되면 다음과 같은 feature_map을 얻게 된다.

feature map을 도식화하는 방법으로 눈으로 직접 feature_map을 보는 것도 좋을 것 같다.
kernel_size: convolution filter의 (행,열)
위와 같은 경우에는 2 X 2 filter가 존재하는 것이다.
strides: filter가 stride하는 단위padding: 경계처리방법으로 filter를 거친 feature map의 크기를 결정짓는 요소이기도 하다.

option이 valid일 경우 유효한 영역만 출력이 되므로 출력이미지 사이즈가 입력 사이즈보다 작아질 것이다.
option이 same일 경우 입력사이즈와 동일하게 행,열을 추가하며 주로 zero padding을 사용한다. zero padding을 사용하면 좋은 점은 영상의 크기를 동일하게 맞출 뿐만 아니라 경계면의 정보까지 살릴 수가 있어 더 좋은 결과를 얻게 된다.
input_shape= (행, 열, 채널수)로 정의하며 모델에서 첫 레이어만 정의한다. 채널수는 흑백일경우 1, 컬러일경우 3으로 설정한다.activation= 활성화함수를 정의한 것으로 우리가 주로 다룰 것은relu,softmax이다. 이는 다음에 다뤄보도록 하겠다.
다른 parameter들은 필요할 때 살펴보도록 하겠다.
parameter 수 계산하기
1 | from tensorflow.keras.models import Sequential |
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 28, 28, 75) 750
_________________________________________________________________
batch_normalization (BatchNo (None, 28, 28, 75) 300
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 75) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 14, 14, 50) 33800
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 50) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 14, 14, 50) 200
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 50) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 7, 7, 25) 11275
_________________________________________________________________
batch_normalization_2 (Batch (None, 7, 7, 25) 100
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 25) 0
_________________________________________________________________
flatten (Flatten) (None, 400) 0
_________________________________________________________________
dense (Dense) (None, 512) 205312
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 25) 12825
=================================================================
Total params: 264,562
Trainable params: 264,262
Non-trainable params: 300
_________________________________________________________________위의 summary는 다른 data들을 학습시킨 결과로 배포할 수 없는 데이터들이기 때문에 summary를 통해서 param number만 계산해 보도록 하겠다.
convolution layer 1의 activation map 크기 계산

Width Output Size = (W - F + 2P) / S + 1
W: input_volume_size(width)
F: kernel_size(width)
P: padding_size(width)
S: strides
첫번째 convolution layer를 지나면 Width = 28, kernel_size(width) = 3, padding_size = 1, strides = 1 이므로 계산하면 width output은 28이 된다.filters의 수가 75이므로 output size = (28,28,75)가 된다.
이를 간단한 그림으로 보이겠다.
1 | Conv2D(3, (2, 2), padding='same', input_shape=(3, 3, 1)) |
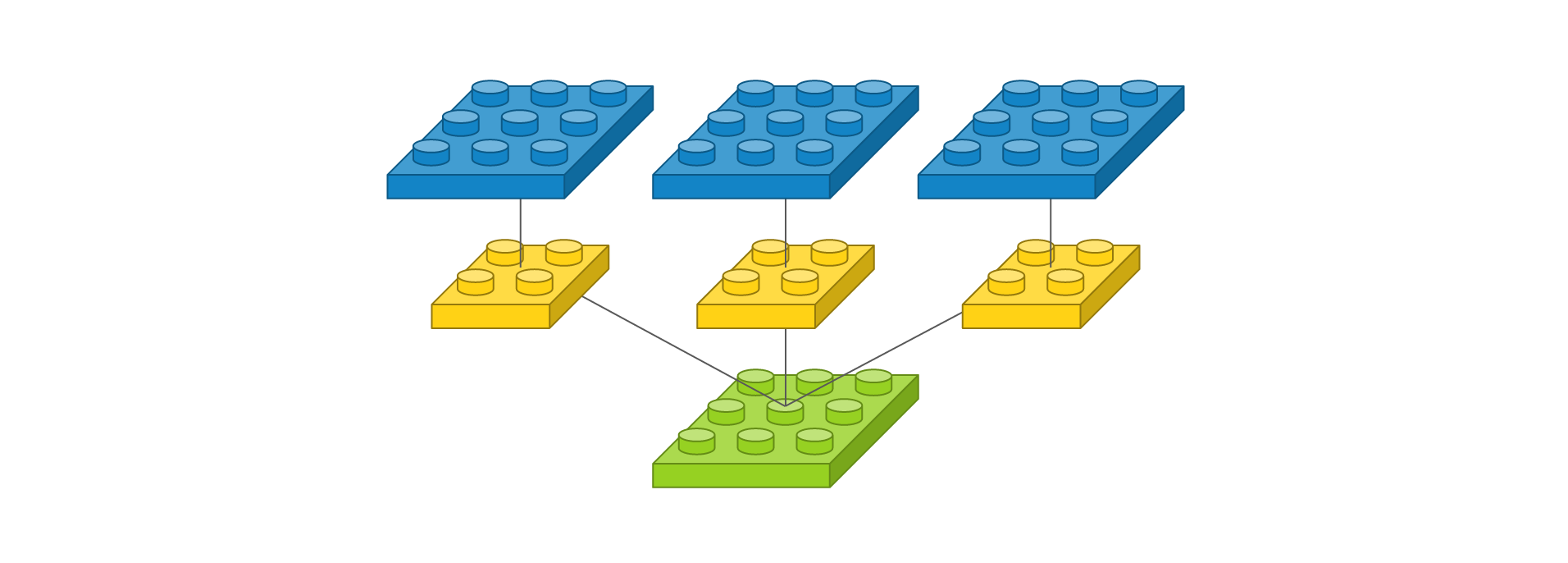
필터가 3개라서 출력 이미지도 필터 수에 따라 3개로 늘어난다.
필터마다 고유한 특징을 뽑아 고유한 출력 이미지로 만들기 때문에 필터의 출력값을 더해서 하나의 이미지로 만들지 않는다.
위의 경우는 채널이 1개일 때고 채널이 여러개일 때를 도식화 한것은 다음과 같다.
1 | Conv2D(2, (2, 2), padding='same', input_shape=(3, 3, 3)) |
input_shape이 (3,3,3)이므로 3X3이미지가 3개의 채널로 존재한다는 것이다. 따라서 필터를 2개를 주고 필터의 사이즈를 2X2로 하게된다면 아래의 그림처럼 필터 1개마다 채널 1개씩 곱이 convolution이 진행되고 다시 한개의 layer로 합쳐지므로 결론적으로는 3X3사이즈의 2개의 채널이 만들어지므로 output_shape은 (3,3,2)일 것이다.
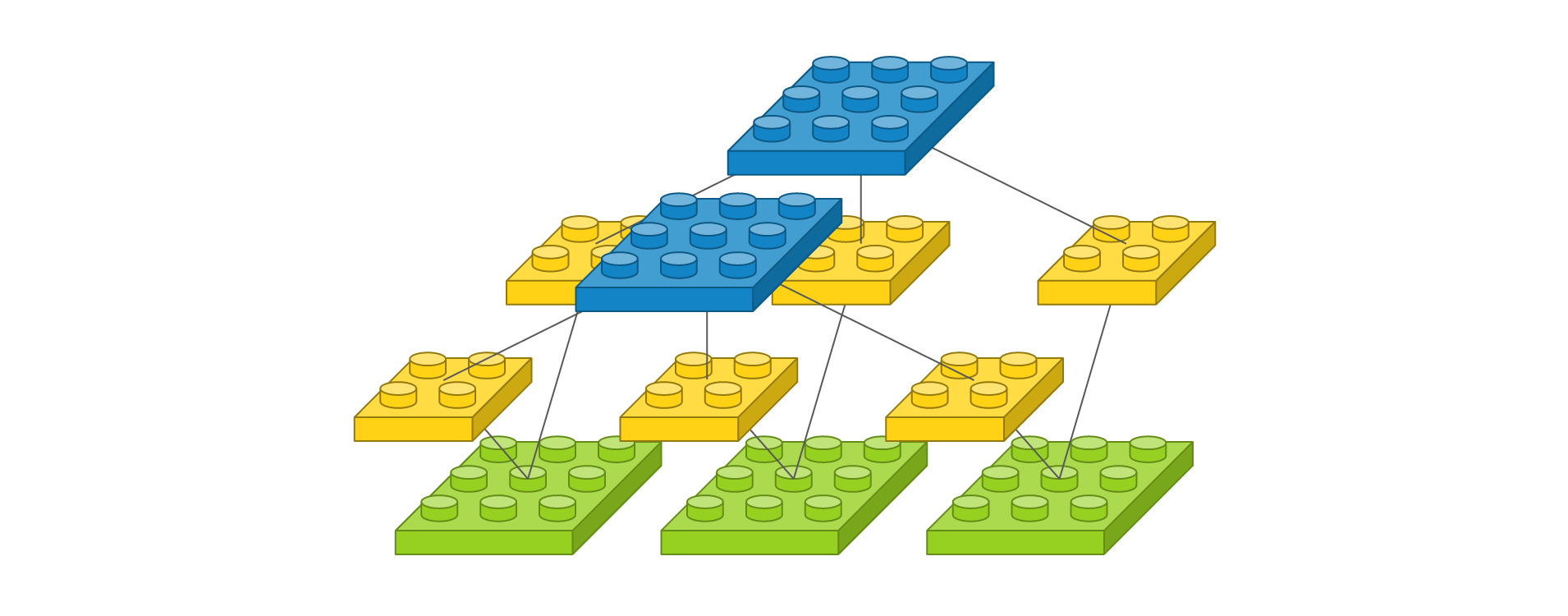
즉 필터의 개수만큼의 layer가 쌓이게 되고 중간에 컨벌루션곱이 이루어진 것이므로 feature map은 당연히 다른 것이다.
이제 파라미터의 수를 구해보겠다. 그 식은 다음과 같다.
1 | number_parameters = out_channels * (in_channels * kernel_h * kernel_w + 1) # 1 for bias |
여기서 out_channels이란 필터의 개수와 동일하다.
1 | in_channels = 1 |
우리의 summary에서 확인한 750은 위와같이 계산된 것이다.
convolution layer 2의 activation map 크기 계산
max_pooling2d를 지나면 output_shape은 (14,14,75)가 된다. 이는 conv2d의 input_shape이 된다. (그래서 첫번째 레이어에서만 input_shape을 정의하는 것이다.)
1 | in_channels = 75 |
두번째 conv2d의 파라미터의 수도 잘계산되었다. 이처럼 Layer들을 지나다보면 in_channels의 수가 증가하여 parameters의 수가 급격히 증가하게 되는데 이를 다루는 방법은 다음에 다뤄보겠다~
Reference
https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
https://underflow101.tistory.com/38?category=826164
https://blog.naver.com/laonple/220587920012